
從Amazon事故啟發網絡管理中該如何處理企業遭遇云停機事故
2015-10-10 14:48 作者:admin 瀏覽量:
美國東部時間清晨六點,該公司負責承載AWS東弗吉尼亞區域負載的名為DynamoDB的大規模NoSQL數據庫發生使用率暴漲狀況——順帶一提,東弗吉尼亞州區域為該公司歷史最悠久、規模最大的九個全球性區域之一。到當日上午七點五十二分,AWS判斷出問題根源:該數據庫的元數據管理機制出現問題,直接影響到其服務的分區與表。
由于AWS服務使用極為復雜的互連機制,因此該問題滾雪球般影響到了總計117項受運行狀況儀表板監控的服務類別當中的34項。從Elastic Comupte Cloud(即彈性計算云,簡稱EC2)到虛擬機、到Glacier存儲服務再到Relational Database Service(即關系數據庫服務)皆受到波及。根據媒體報道所言,其它采用AWS方案的企業客戶亦遭到影響,其中包括Netflix、IMDB、Tinder、Pocket以及Buffer等知名公司。
那么我們該從此次事故當中吸取哪些經驗教訓?下面請大家一同探討其中的三項重點。(網絡維護服務公司)
1.云服務巨頭也有失蹄的時候
Amazon Web Services是目前公有IaaS云領域當之無愧的王者——雖然微軟公司似乎也在這類業務身上砸下重金,但似乎仍然無法動搖Amazon的強勢地位。上周日的事故則提醒我們,即使是規模最大、經驗最為老到的云服務供應商,也仍然有可能遭遇意料之外的突發狀況。
2.時刻準備迎接停機事故
考慮到即使是市場上成熟程度最高的云方案也仍然有可能——或者說實際遭遇到長達六個小時的服務停機,客戶應當提前為此做好準備。AWS長久以來一直建議客戶對自有系統進行架構規劃,從而更加主動地應對可能出現的虛擬機或者其它服務停機。
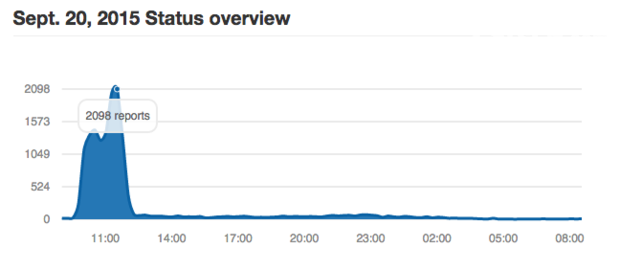
DownDetector.com網站統計圖表顯示,Netflix公司上周日早晨的錯誤報告頻率遠高于正常狀況。不過根據該公司的一位發言人所說,其服務并沒有受到顯著影響。(電腦桌面維護外包)
作為Amazon公司旗下規模最大且最具知名度的云服務客戶之一,Netflix公司通過發言人強調稱,此次停機事故給其服務造成的影響被控制在了最低程度,這是因為其以自動化方式將工作負載從出現問題的美國東部區域設施遷移到了其它運行正常的區域。任何使用AWS承載關鍵性業務應用的客戶都應當對系統架構進行調整,從而確保其能夠在相關云服務出現意外狀況時做好應對措施。Netflix公司還開發出了一系列開源工具,旨在幫助自身系統進行隨機崩潰測試。盡管Netflix方面并不承認其客戶因此次事故受到嚴重影響,不過第三方停機追蹤站點卻發布報告稱,Netflix在上周日早間遭遇到遠超過正常水平的服務中斷頻率。換言之,即使是做好了充分準備的高水平客戶,也沒辦法完全避免云服務中斷造成的影響。
3.“莫謂言之不預”
福布斯網站的一位博主認為,此次服務中斷并不會改變云計算的未來普及趨勢。我個人基本同意這種看法。如果大家身為AWS的擁護者,那么肯定會從積極的角度看待此次事件,例如中斷事故的發生頻率遠低于以往,如果客戶采取AWS推薦的最佳實踐、那么這些意外也不會造成太大影響等等。
不過換個角度來看,像上周日這樣的服務中斷狀況將成為有力證據,促使那些不愿將工作負載交給公有云打理的客戶抱持更加頑固的心態。
事實上中斷事故是不可避免的,其可能出現在公有云服務中、任意供應商處甚至連企業自己負責運行的內部數據中心也不放過。而這正是IT事務的本質與宿命,所以一味強調公有云存在可用性問題確實不太客觀。(it外包)
艾銻無限是中國領先IT外包服務商,專業為企業提供IT運維外包、電腦維護、網絡維護、網絡布線、辦公設備維護、服務器維護、數據備份恢復、門禁監控、網站建設等多項IT服務外包,服務熱線:400-650-7820 聯系電話:010-62684652 咨詢QQ1548853602 地址:北京市海淀區北京科技會展2號樓16D,用心服務每一天,為企業的發展提升更高的效率,創造更大的價值。
更多的IT外包信息盡在艾銻無限http://www.richjn.cn
相關文章



 關閉
關閉