
微軟新作,ImageBERT雖好,千萬級數據集才是亮點
2020-02-05 15:39 作者:
迎戰疫情,艾銻無限用愛與您同行
為中國中小企業提供免費IT外包服務

這次的肺炎疫情對中國的中小企業將會是沉重的打擊,據釘釘和微信兩個辦公平臺數據統計現有2億左右的人在家遠程辦公,那么對于中小企業的員工來說不懂IT技術將會讓他們面臨的最大挑戰和困難。
電腦不亮了怎么辦?系統藍屏如何處理?辦公室的電腦在家如何連接?網絡應該如何設置?VPN如何搭建?數據如何對接?服務器如何登錄?數據安全如何保證?數據如何存儲?視頻會議如何搭建?業務系統如何開啟等等一系列的問題,都會困擾著并非技術出身的您。

好消息是當您看到這篇文章的時候,就不用再為上述的問題而苦惱,您只需撥打艾銻無限的全國免費熱線電話:400 650 7820,就會有我們的遠程工程師為您解決遇到的問題,他們可以遠程幫您處理遇到的一些IT技術難題。
如遇到免費熱線占線,您還可以撥打我們的24小時值班經理電話:15601064618或技術經理的電話:13041036957,我們會在第一時間接聽您的來電,為您提供適合的解決方案,讓您無論在家還是在企業都能無憂辦公。
那艾銻無限具體能為您的企業提供哪些服務呢?

第一版塊是保障性IT外包服務:如電腦設備運維,辦公設備運維,網絡設備運維,服務器運維等綜合性企業IT設備運維服務。
第二版塊是功能性互聯網外包服務:如網站開發外包,小程序開發外包,APP開發外包,電商平臺開發外包,業務系統的開發外包和后期的運維外包服務。
第三版塊是增值性云服務外包:如企業郵箱上云,企業網站上云,企業存儲上云,企業APP小程序上云,企業業務系統上云,阿里云產品等后續的云運維外包服務。
您要了解更多服務也可以登錄艾銻無限的官網:www.bjitwx.com查看詳細說明,在疫情期間,您企業遇到的任何困境只要找到艾銻無限,能免費為您提供服務的我們絕不收一分錢,我們全體艾銻人承諾此活動直到中國疫情結束,我們將這次活動稱為——春雷行動。
以下還有我們為您提供的一些技術資訊,以便可以幫助您更好的了解相關的IT知識,幫您渡過疫情中辦公遇到的困難和挑戰,艾銻無限愿和中國中小企業一起共進退,因為我們相信萬物同體,能量合一,只要我們一起齊心協力,一定會成功。再一次祝福您和您的企業,戰勝疫情,您和您的企業一定行。
微軟新作,ImageBERT雖好,千萬級數據集才是亮點
繼 2018 年谷歌的 BERT 模型獲得巨大成功之后,在純文本之外的任務上也有越來越多的研究人員借鑒了 BERT 的思維,開發出各種語音、視覺、視頻融合的 BERT 模型。雷鋒網 AI 科技評論曾專門整理并介紹了多篇將BERT應用到視覺/視頻領域的重要論文,其中包括最早的VideoBERT以及隨后的ViLBERT、VisualBERT、B2T2、Unicoder-VL、LXMERT、VL-BERT等。其中VL-BERT是由來自中科大、微軟亞研院的研究者共同提出的一種新型通用視覺-語言預訓練模型。繼語言BERT之后,視覺BERT隱隱成為一種新的研究趨勢。
近期,來自微軟的Bing 多媒體團隊在arXiv上也同樣發表了一篇將BERT應用到視覺中的論文《ImageBERT: Cross-modal Pre-training with Large-scale Weak-supervised Image-Text Data》
在這篇文章中,作者提出了一種新的視覺語言預訓練模型ImageBERT,并從網絡上收集了一個大型的弱監督圖像-文本數據集LAIT,包含了 10M(1千萬)的 Text-Image pairs,這也是目前最大的一個數據集。利用ImageBERT模型和LAIT數據集進行預訓練,在MSCOCO和Flicker30k上進行文本到圖像、圖像到文本的檢索任務上獲得了不錯的結果。
2、背景及相關工作
隨著Transformer的提出并廣泛應用于跨模態研究,近一年以來,各項任務上獲得的結果被推向了一個新的“珠穆朗瑪峰”。雖然幾乎所有最新的工作都是基于Transformer,但這些工作在不同的方面各有不同。
模型架構的維度:
BERT是面向輸入為一個或兩個句子的 NLP 任務的預訓練模型。為了將 BERT 架構應用于跨模態任務中,現在已有諸多處理不同模態的方法。ViLBERT和LXMERT 先分別應用一個單模態Transformer到圖像和句子上,之后再采用跨模態Transformer來結合這兩種模態。其他工作如VisualBERT, B2T2,Unicoder-VL, VL-BERT, Unified VLP,UNITER等等,則都是將圖像和句子串聯為Transformer的單個輸入。很難說哪個模型架構更好,因為模型的性能非常依賴于指定的場景。
圖像視覺標記維度:
最近幾乎所有的相關論文都將目標檢測模型應用到圖像當中,同時將經檢測的感興趣區(ROIs) 用作圖像描述符,就如語言標記一般。與使用預訓練的檢測模型的其他工作不同,VL-BERT 結合了圖像-文本聯合嵌入網絡來共同訓練檢測網絡,同時也將全局圖像特征添加到模型訓練中。
可以發現,基于區域的圖像特征是非常好的圖像描述符,它們形成了一系列可直接輸入到 Transformer 中的視覺標記。
預訓練數據維度:
與可以利用大量自然語言數據的預訓練語言模型不同,視覺-語言任務需要高質量的圖像描述,而這些圖像描述很難免費獲得。Conceptual Captions 是最為廣泛應用于圖像-文本預訓練的數據,有 3 百萬個圖像描述,相對而言比其他的數據集都要大。UNITER 組合了四個數據集(Conceptual Captions,SBU Captions,Visual Genome, MSCOCO),形成了一個960萬的訓練語料庫,并在多個圖像-文本跨模態任務上實現了最佳結果。LXMERT將一些VQA訓練數據增添到預訓練中,并且在VQA任務上也獲得了最佳結果。
我們可以發現,數據的質量和大小對于模型訓練而言至關重要,研究者們在設計新的模型時應該對此給予更大的關注。
3、數據集收集
基于語言模型的BERT,可以使用無限的自然語言文本,例如BooksCorpus或Wikipedia;與之不同,跨模態的預訓練需要大量且高質量的vision-language對。
目前最新的跨模態預訓練模型常用的兩個數據集分別是:
The Conceptual Captions (CC) dataset:包含了3百萬帶有描述的圖像,這些圖像是從網頁的Alt-text HTML屬性中獲取的;
SBU Captions:包含了1百萬用戶相關標題的圖像。
但這些數據集仍然不夠大,不足以對具有數億參數的模型進行預訓練(特別是在將來可能還會有更大的模型)。
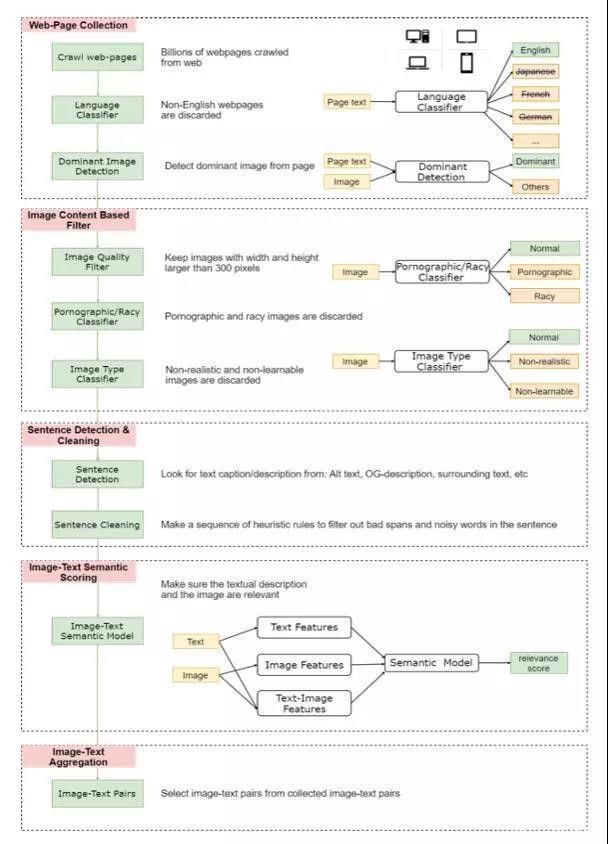
為此,作者設計了一種弱監督的方法(如下圖所示),從Web上收集了一個大規模的圖像文本數據集。

弱監督數據收集流程
先是從網絡上收集數億的網頁,從中清除掉所有非英語的部分,然后從中收集圖片的URLs,并利用HTML 標記和DOM樹特征檢測出主要圖片(丟棄非主要圖片,因為它們可能與網頁無關)。
隨后僅保留寬度和高度均大于300像素的圖片,并將一些色情或淫穢內容的圖片以及一些非自然的圖片丟棄。
針對剩下的圖片,將HTML中用戶定義元數據(例如Alt、Title屬性、圖片周圍文本等)用作圖像的文本描述.
為了確保文字和圖片在語義上是相關的,作者利用少量image-text監督數據,訓練了一個弱image-text語義模型來預測<text, image>在語義上是否相關。用這個模型從十億規模的image-text 對中過濾掉相關性不高的數據,從而生成的數據集LAIT(Large-scale weAk-supervised Image-Text),其中包含了 一千萬張圖片,圖片描述的平均長度為13個字。
LAIT數據集中的樣本
4、ImageBERT模型
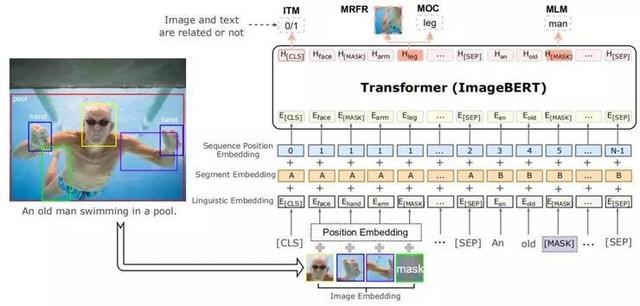
如上圖所示,ImageBERT模型的總體架構和BERT類似,都采用了Transformer作為最基礎的架構。不同之處在于將圖像視覺的標記和問題標注作為輸入。注意其中圖像視覺標記是從Faster-RCNN模型提取的ROL特征。
通過一層嵌入層將文本和圖像編碼成不同的嵌入,然后將嵌入傳送到多層雙自我注意Transformer中來學習一個跨模態Transformer,從而對視覺區域和文字標記之間的關系進行建模。
1)嵌入建模
整個嵌入建模分為三個部分:語言嵌入、圖像嵌入、序列位置和片段嵌入。
在語言嵌入模塊中采用了與BERT相似的詞預處理方法。具體而言,是用WordPiece方法將句子分成(標記)n個子詞{w0,...,wn-1}。一些特殊的標記,例如CLS和SEP也被增添到標記的文本序列里。每個子詞標記的最終嵌入是通過組合其原始單詞嵌入、分段嵌入和序列位置嵌入來生成的。
與語言嵌入類似,圖像嵌入也是通過類似的過程從視覺輸入中產生的。用Faster-RCNN從 o RoIs中提取特征(記為{r0,...ro-1}),從圖像中提取特征,從而讓這兩個特征代表視覺內容。檢測到的物體對象不僅可以為語言部分提供整個圖像的視覺上下文(visual contexts),還可以通過詳細的區域信息與特定的術語相關聯。另外,還通過將對象相對于全局圖像的位置編碼成5維向量來向圖像嵌入添加位置嵌入。5維向量表示如下:
其中,(xtl,ytl)以及(xbr,ybr)分別代表邊界框的左上角和右下角坐標。5維向量中的第五個分向量相對于整個圖像的比例面積。
另外,物體特征和位置嵌入都需要通過語言嵌入投影到同一維度。e(i)代表每個圖像的RoI。其計算通過加總對象嵌入、分段嵌入、圖像位置嵌入以及序列位置嵌入獲得。這意味著每個嵌入被投影到一個向量之中,然后用同樣的嵌入大小作為Transformer 隱藏層的尺寸,最后采用正則化層。
在序列位置和片段嵌入中,因為沒有檢測到Rol的順序,所以其對所有的視覺標記使用固定的虛擬位置,并且將相應的坐標添加到圖像嵌入中。
2)多階段預訓練
不同的數據集來源不同,所以其數據集質量也就不同。為了充分利用不同類型的數據集,作者提出了多階段預訓練框架。如下圖所示。
其主要思想是先用大規模域外數據訓練預先訓練好的模型,然后再用小規模域內數據訓練。在多階段預訓練中,為了有順序地利用不同種類的數據集,可以將幾個預訓練階段應用到相同的網絡結構。
更為具體的,在ImageBERT模型中使用兩階段的預訓練策略。第一個階段使用LAIT數據集,第二個階段使用其他公共數據集。注意,兩個階段應使用相同的訓練策略。
3)預訓練任務
在模型預訓練過程中,設計了四個任務來對語言信息和視覺內容以及它們之間的交互進行建模。四個任務分別為:掩碼語言建模(Masked Language Modeling)、掩碼對象分類(Masked Object Classification)、掩碼區域特征回歸(Masked Region Feature Regression)、圖文匹配(Image-Text Matching)。
掩碼語言建模簡稱MLM,在這個任務中的訓練過程與BERT類似。并引入了負對數似然率來進行預測,另外預測還基于文本標記和視覺特征之間的交叉注意。
掩碼對象分類簡稱MOC,是掩碼語言建模的擴展。與語言模型類似,其對視覺對象標記進行了掩碼建模。并以15%的概率對物體對象進行掩碼,在標記清零和保留的概率選擇上分別為90%和10%。另外,在此任務中,還增加了一個完全的連通層,采用了交叉熵最小化的優化目標,結合語言特征的上下文,引入負對數似然率來進行預測正確的標簽。
掩碼區域特征回歸簡稱MRFR,與掩碼對象分類類似,其也對視覺內容建模,但它在對象特征預測方面做得更精確。顧名思義,該任務目的在于對每個掩碼對象的嵌入特征進行回歸。在輸出特征向量上添加一個完全連通的圖層,并將其投影到與匯集的輸入RoI對象特征相同的維度,然后應用L2損失函數來進行回歸。
值得注意的是,上述三個任務都使用條件掩碼,這意味著當輸入圖像和文本相關時,只計算所有掩碼損失。
在圖文匹配任務中,其主要目標是學習圖文對齊(image-text alignment)。具體而言對于每個訓練樣本對每個圖像隨機抽取負句(negative sentences),對每個句子隨機抽取負圖像(negative images),生成負訓練數據。在這個任務中,其用二元分類損失進行優化。
4)微調任務
經過預訓練,可以得到一個“訓練有素”的語言聯合表征模型,接下來需要對圖文檢索任務模型進行微調和評估,因此本任務包含圖像檢索和文本檢索兩個子任務。圖像檢索目的是給定輸入字幕句能夠檢索正確的圖像,而圖像文本檢索正好相反。經過兩個階段的預訓練后,在MSCoCO和Flickr30k數據集上對模型進行了微調,在微調過程中,輸入序列的格式與預訓練時的格式相同,但對象或單詞上沒有任何掩碼。另外,針對不同的負采樣方法提出了兩個微調目標:圖像到文本和文本到圖像。
為了使得提高模型效果,還對三種不同的損失函數進行了實驗,這三種損失函數分別為:二元分類損失、多任務分類損失、三元組損失(Triplet loss)。關于這三種微調損失的組合研究,實驗部分將做介紹。
5、實驗
針對圖像-文本檢索任務,作者給出了零樣本結果來評估預訓練模型的質量和經過進一步微調后的結果。下面是在 MSCOCO 和Flickr30k 數據集的不同設置下,對ImageBERT模型和圖像檢測和文本檢索任務上其他最先進的方法進行的比較。
1)評估預訓練模型
如前面所提到,模型經過了兩次預訓練。首先是在 LAIT 數據集上,采用從基于BERT 的模型初始化的參數對模型進行了預訓練;然后又在公開數據集(Conceptual Captions, SBU Captions)上對模型進行二次預訓練。具體過程和實驗設置請參考論文。
在沒有微調的情況下,作者在Flickr30k和MSCOCO測試集上對預訓練模型進行了評估,如下:
零樣本結果如表 1 所示,我們可以發現,ImageBERT預訓練模型在MSCOCO 獲得了新的最佳結果,但在Flickr30k數據集上卻比 UNITER模型的表現稍差。
在微調后,ImageBERT模型獲得了有競爭力的結果,相關情況在表2 部分進行說明。值得一提的是,相比于其他僅有一個預訓練階段的方法,這種多階段的預訓練策略在預訓練期間學到了更多有用的知識,因而能夠有助于下游任務的微調階段。
2)評估微調模型
在檢索任務上微調后的最終結果如表2 所示。我們可以看到,ImageBERT模型在Flickr30k 和 MSCOCO(同時在 1k和 5k的測試集)上都實現了最佳表現,并且超越了所有的其他方法,從而證明了本文所提的面向跨模態聯合學習的 LAIT 數據和多階段預訓練策略的有效性。
3)消融實驗
作者也在 Flickr3k 數據集上對預訓練數據集的不同組合、全局視覺特征的顯示、不同的訓練任務等進行了消融實驗,以進一步研究ImageBERT模型的架構和訓練策略。
預訓練數據集
作者使用不同數據集的組合來進行預訓練實驗。結果如表3所示。CC表示的僅在 Conceptual Captions 數據集上進行預訓練;SBU 表示僅在 SBU Captions數據集上進行預訓練;LAIT+CC+SBU表示使用LAIT, Conceptual Caption 和 SBU Captions的組合數據集進行預訓練;LAIT → CC+SBU 表示使用 LAIT 來完成第一階段的預訓練,之后使用 Conceptual Captions和SBU Captions 數據集來做第二階段的預訓練。
可以看到,用多階段的方法來使用三種不同的域外數據集,獲得了比其他方法明顯更好的結果。
全局圖像特征
值得注意的是,檢測的ROIs可能并不包含整個圖像的所有信息。因此,作者也嘗試將全局圖像特征添加到視覺部分。文章使用了三個不同的CNN 模型(DenseNet,Resnet, GoogleNet)從輸入圖像上提取全局視覺特征,然而卻發現并非所有的指標都會提高。結果如表4的第1部分所示。
預訓練損失
作者也將由UNITER引起的MRFR損失添加到預訓練中,結果在零樣本結果上獲得略微提高,結果如表4 的第2 部分所示。這意味著增加一個更難的任務來更好地對視覺內容進行建模,有助于視覺文本聯合學習。
圖像中的目標數量 (RoIs)
為了理解ImageBERT模型的視覺部分的重要性,作者基于不同的目標數量進行了實驗。如表4的第4部分所示,ImageBERT模型在目標最少(目標數量與ViLBERT一樣)的情況下,在檢索任務上并沒有獲得更好的結果。
可以得出結論,更多的目標確實能夠幫助模型實現更好的結果,因為更多的 RoIs 有助于理解圖像內容。
微調損失
針對在第4部分所提到的三項損失,作者嘗試在微調期間進行不同的組合。如表4的第4 部分所示,模型通過使用二元交叉熵損失(Binary Cross-Entropy Loss),本身就能在圖像-文本檢索任務上獲得最佳的微調結果
相關文章



 關閉
關閉